

Les fausses SERPs de Google : la « soupe Google » qui piège les bots de suivi et pourquoi ça ne m’avait jamais autant surpris en 20 ans de SEO
Décryptage du web épisode 6
Vingt ans. Vingt ans que j’observe Google évoluer, muter, surprendre. J’ai vécu les grandes purges Panda et Penguin, les bouleversements du passage au mobile-first, l’arrivée de RankBrain, les core updates à répétition… Mais ce que j’ai observé depuis début 2026 et particulièrement entre février et mars, m’a franchement pris de court. Et je pèse mes mots, parce que ça ne m’arrive plus souvent.
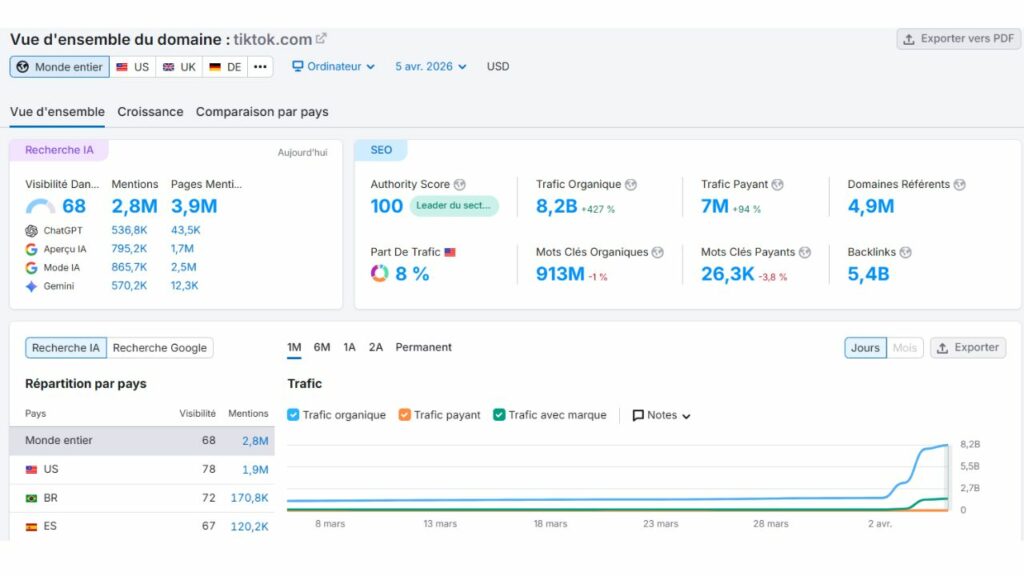
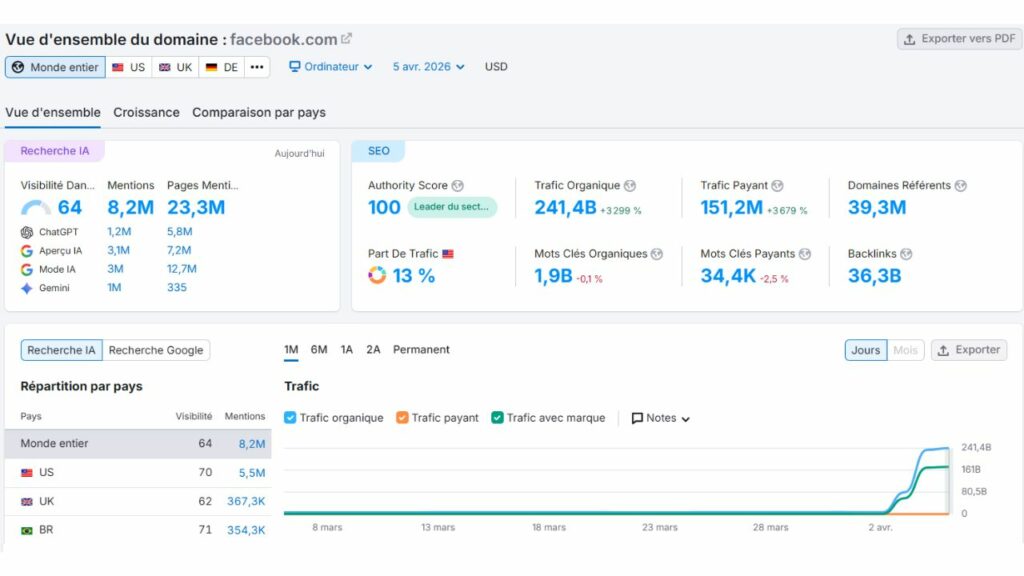
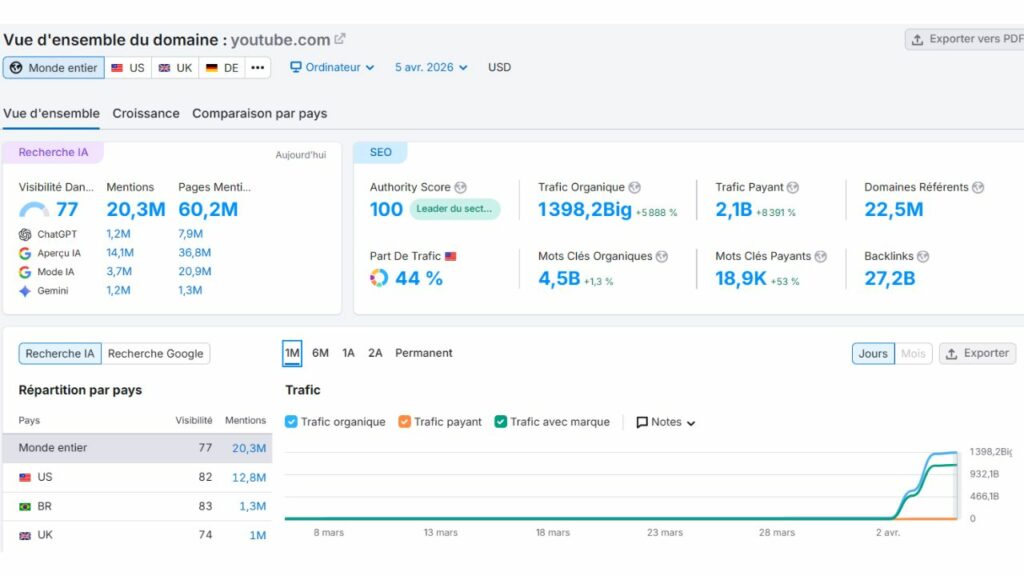
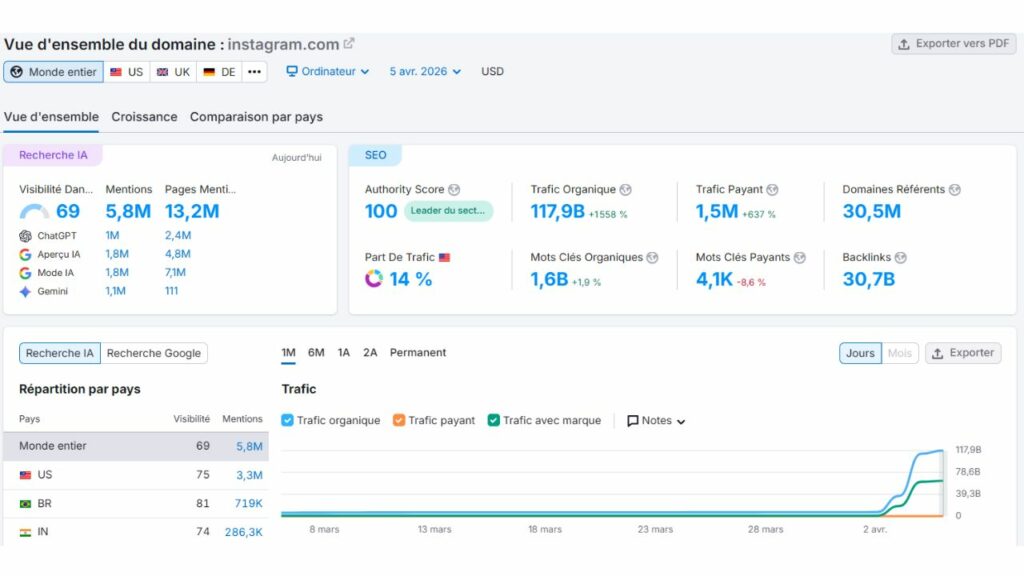
Pour la première fois de ma carrière, j’ai vu des outils comme Semrush, Ahrefs, Monitorank ou Semscraper rapporter des phénomènes que je ne savais tout simplement pas comment interpréter au premier abord : des hausses massives et totalement fantômes de visibilité pour YouTube, Dailymotion, TikTok, Instagram ou Facebook, sur des requêtes où ces plateformes n’ont objectivement aucune légitimité. Le Sensor de Semrush a frôlé les 9,5/10, ce que la communauté appelle un « Googlequake ». Sauf que là, pour une fois, ce n’était pas vraiment un séisme algorithmique. C’était autre chose. Quelque chose de nouveau. Ce que j’ai fini par appeler la « soupe Google », ou Shadow SERP.
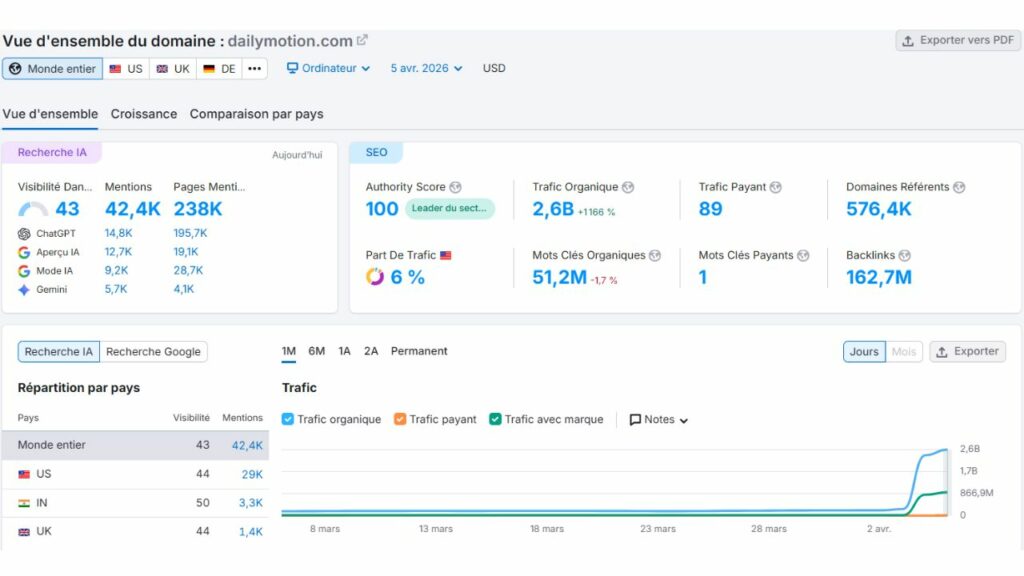
Alors, c’est quoi exactement cette « soupe Google » ?
Google a déployé un système anti-scraping d’une sophistication que je n’avais jamais vue à cette échelle. Dès qu’un bot est détecté : volume élevé de requêtes, user-agent suspect, absence d’exécution JavaScript, patterns de scraping typiques, le moteur ne le bloque plus. Il fait bien pire : il lui sert des résultats volontairement faussés.
Dans ces Shadow SERPs :
- YouTube, Dailymotion, TikTok ou Instagram envahissent les résultats, parfois jusqu’en pages 2 et 3, même sur des requêtes transactionnelles ou purement textuelles où aucun utilisateur humain ne les verra jamais.
- Les résultats organiques classiques : sites web, e-commerces, articles de blog sont repoussés, dupliqués, voire absents.
- Les outils de tracking reçoivent donc une vision totalement déconnectée de la réalité.
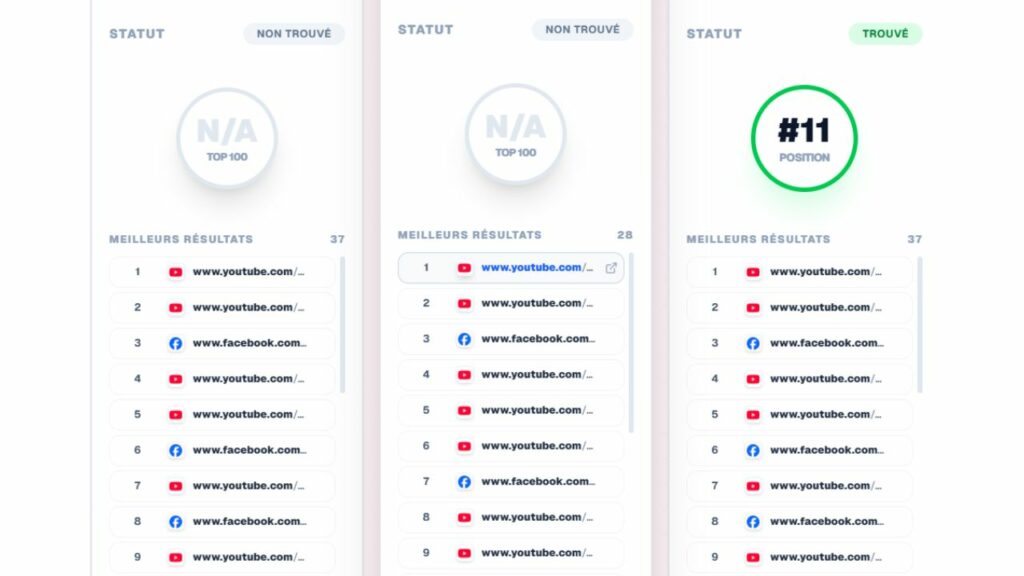
Ce n’est pas un bug. C’est une stratégie. Monitorank l’a documenté dès le 3 février 2026 avec une chute brutale des courbes, suivie d’un retour massif de vidéos dans les SERPs. Google a temporairement relâché la pression, avant de renforcer massivement sa détection le 27 mars, en plein déploiement de la Core Update.
Fabien, co-fondateur de Monitorank et Semscraper, l’a formulé très clairement sur X le 1er avril : « La forte hausse vient du fait que Google fournit de la soupe avec du YouTube/Dailymotion/TikTok/Instagram aux bots, ce n’est en aucun cas une vraie augmentation de visibilité. » Son outil disposait déjà d’un correctif depuis février et il l’a maintenu malgré le renforcement du 27 mars.
Les conséquences concrètes : une explosion fantôme qui fausse tout
Quand Google sert de la soupe à vos outils, les effets sont immédiats et potentiellement dévastateurs pour vos décisions :
Des hausses fantômes spectaculaires. YouTube, TikTok, Instagram semblent soudainement dominer des milliers de requêtes dans Semrush ou Ahrefs. Des visuels impressionnants… qui ne correspondent à rien dans la vraie vie.
De fausses alertes de volatilité. Le Sensor s’emballe à 9,5/10. On parle de « séisme » le 1er avril 2026. Des experts s’affolent. En réalité, c’est en grande partie un artefact de mesure.
Des décisions stratégiques erronées. J’ai vu des équipes SEO réallouer des budgets vers du contenu vidéo, paniquer inutilement, ou optimiser dans la mauvaise direction, tout ça à cause de données corrompues qu’elles prenaient pour argent comptant.
Ce que vous voyez dans Semrush, ce n’est plus nécessairement le reflet du comportement des utilisateurs humains. C’est parfois juste ce que Google choisit de montrer aux robots.
Mais la soupe n’explique pas tout : il y a aussi un vrai Googlequake
Soyons honnêtes : au-delà des Shadow SERPs, les SERPs sont réellement instables depuis janvier 2026. Des positions fluctuent de plusieurs places en quelques heures. Des trafics organiques chutent ou explosent sans explication apparente. Le Sensor reste en zone très élevée depuis le début de l’année.
Deux mises à jour majeures en mars ont amplifié le phénomène :
- 24 mars : Spam Update (terminé en moins de 24h) ciblant le spam IA, le thin content, les schémas de liens abusifs.
- 27 mars : Core Update (déploiement sur environ deux semaines) recalibrant la pertinence et l’utilité globale des contenus.
Google déploie entre 500 et 600 modifications algorithmiques par an, avec une accélération nette en 2026, liée à la transition vers l’IA : AI Overviews, Gemini, tout bouge en même temps.
Pourquoi Google fait-il ça ? Et pourquoi maintenant ?
J’ai ma propre lecture de la situation, forgée après deux décennies à observer ce moteur.
Protéger ses données et son monopole. Les bots de tracking coûtent cher en ressources serveur. En corrompant les données qu’il leur envoie, Google rend le reverse-engineering de son algorithme beaucoup plus difficile et coûteux.
Rendre le scraping commercial insoutenable. En 2025, Google a supprimé le paramètre &num=100 (multipliant par 10 le nombre de requêtes nécessaires), rendu JavaScript obligatoire, et engagé des poursuites judiciaires contre SerpApi via DMCA en décembre 2025. Pendant ce temps, Googlebot crawle librement l’intégralité du web pour entraîner Gemini. Le double standard a été largement dénoncé par la communauté, et franchement, il est difficile de lui donner tort.
Naviguer des objectifs contradictoires. Améliorer l’expérience utilisateur avec les AI Overviews (qui font mécaniquement chuter les CTR), lutter contre le spam via SpamBrain, protéger les éditeurs, intégrer l’IA générative… Google jongle avec des impératifs qui se contredisent parfois. Les mises à jour successives ressemblent souvent à des ajustements à tâtons.
Comme je l’ai lu sur X dans un commentaire qui m’a fait sourire : « Google qui piège les scrapers pendant que Googlebot crawle tout pour son IA, c’est culotté. » Culotté, oui. Mais cohérent avec la logique de protection d’un écosystème de données qui vaut des milliards.
Comment s’en sortir ? Ce que je fais, et ce que je recommande
Voilà ce que j’applique aujourd’hui, après avoir digéré tout ça :
Retour aux sources first-party. Google Search Console et Google Analytics restent la seule vérité qui compte. En cas de divergence avec les outils tiers, je fais toujours confiance à la GSC. Toujours.
Bien choisir ses outils. Tous les scrapers ne se valent plus. Ceux qui ont investi dans des correctifs anti-soupe, des infrastructures de secours et une détection active des biais : comme Monitorank ont une longueur d’avance réelle.
Revenir à l’humain. J’augmente le monitoring manuel, les tests en conditions réelles, l’analyse qualitative. L’équation « position = trafic » ne suffit plus. Elle n’a d’ailleurs jamais vraiment suffi, mais là, c’est criant.
Miser sur l’E-E-A-T et le contenu réel. L’expérience authentique, l’expertise vérifiable et la confiance construite dans la durée résistent mieux que jamais. Les sites portés par du vécu réel continuent à gagner. Les contenus IA low-value s’effondrent.
Relativiser le Sensor. Un score à 9,5/10 n’est plus automatiquement synonyme d’update majeur. Il peut signaler une vague de Shadow SERPs. Prenez du recul avant d’alerter votre client à minuit.
Ma conclusion du moment
Google ne se contente plus de lutter contre le spam. Il défend activement son écosystème de données contre tous ceux qui veulent en extraire trop facilement et il le fait avec des outils que je n’avais jamais vus déployés à cette échelle.
Est-ce que ça m’inquiète ? Honnêtement, non. Parce que c’est ce que le SEO a toujours été : une discipline d’adaptation permanente. Chaque fois que je me suis dit « cette fois, c’est différent », il s’est avéré que c’était juste la prochaine évolution à intégrer. Celle-ci en fait partie.
Ce qui a changé, c’est que les données sur lesquelles nous nous appuyions depuis des années sont désormais potentiellement corrompues à la source. Et ça, c’est effectivement nouveau. Ça exige une vigilance accrue, une triangulation systématique des informations, et une forme d’humilité face aux chiffres qu’on nous présente.
Et vous ?Avez-vous observé ces hausses fantômes de YouTube ou TikTok dans vos outils ces dernières semaines ? Si oui, vous savez maintenant ce que vous regardez vraiment. Restez vigilants, croisez vos données, et concentrez-vous sur l’essentiel : du contenu utile, de l’expérience réelle, et des données que vous contrôlez vraiment.





